3.5 Verarbeitung von MARC21 mit OpenRefine
Ein möglicher Weg zum Laden von Metadaten in den Suchindex Solr ist die Transformation der umfangreichen bibliothekarischen Metadaten in eine klassische Tabellenstruktur mit wenigen Spalten, in denen wir die für die Suche relevante Daten zusammenführen:
- Spaltenüberschriften werden zu Feldern im Suchindex
- Mehrere Werte in einer Tabellenzelle können mit einem Trennzeichen eingegeben werden (das Trennzeichen muss eindeutig sein, darf also nicht bereits in den Daten vorkommen)
- OpenRefine bietet als Export vorrangig CSV oder TSV an. Das kann der Suchindex Solr problemlos indexieren.
Nach der Transformation könnten die Daten beispielsweise so aussehen:
| id | Titel | AutorInnen | ... |
|---|---|---|---|
| 123 | Zur Elektrodynamik bewegter Körper | Einstein, Albert | ... |
| 299 | Albert Einstein | Ziegelmann, Horst␟Fischer, Ernst Peter␟Renn, Jürgen | ... |
| ... | ... | ... | ... |
Natürlich könnten wir auch mit einem anderen Werkzeug (z.B. XSLT) die Dateien direkt als XML transformieren und in den Suchindex laden, aber Tabellendaten sind eben einfach besonders übersichtlich und in dieser Struktur fallen Ungereimtheiten in den Daten sofort ins Auge. Für unsere erste Datenquelle im Discovery-System also eine gute Übung.
Eigenes Schema oder einem Metadatenstandard folgen?
Es ist sicher klar, dass wir nicht die umständlichen MARC-Zahlen und Codes als Spaltennamen in unseren Katalog übernehmen wollen, sondern sprechende Namen wie TItel, AutorInnen und so weiter. Doch welche Daten brauchen wir in welcher Form für den Katalog?
Überlegen Sie:
- Welche Informationen wollen Sie in Ihrem Bibliothekskatalog anbieten?
- Wer soll die Hauptzielgruppe sein?
- Welche Filtermöglichkeiten (Facetten) wollen Sie anbieten?
- Welche Kurzinformationen (Unterscheidungsmerkmale) sollen in der Trefferliste stehen?
- Welche Informationen sollen in der Vollanzeige dargestellt werden?
Wenn Sie ein innovatives Discovery-System auf Basis von verschiedenen heterogenen Datenquellen bauen wollen, dann kann auch die absichtliche Reduktion auf wenige Felder helfen ("Simplicity"). Wichtig für das Nutzererlebnis ("User Experience") ist, dass die Felder konsistent belegt sind und Trefferliste und Facetten nützliche und eindeutige Unterscheidungsmerkmale beinhalten. Bei der Datentransformation haben Sie die Chance einige Unstimmigkeiten zu bereinigen und Informationen clever zu aggregieren, so dass die Daten trotz verschiedener Quellen einigermaßen einheitlich durchsuchbar sind.
Haben Sie eigene Vorstellungen? Falls nicht, dann orientieren Sie sich an Dublin Core, denn diese Initiative hatte von Beginn an das Ziel, einen gemeinsamen Mindeststandard zu definieren und entsprechend übersichtlich sind die Felder. Wenn Sie noch nicht mit MARC gearbeitet haben und die passenden Zahlen und Codes nicht im Kopf haben, dann orientieren Sie sich an der Empfehlung der Library of Congress für einen "MARC to Dublin Core Crosswalk".
Aufgabe 1: Testdaten importieren und zur weiteren Bearbeitung umstrukturieren
Arbeitsspeicher für OpenRefine freigeben
Für das Laden und Transformieren der 2075 Beispieldatensätze benötigt OpenRefine etwa 1,5 GB Arbeitsspeicher. Als Standardeinstellung verwendet OpenRefine jedoch maximal 1,4 GB Arbeitsspeicher. Wenn während der Transformation der Speicher ausgeht, wird OpenRefine erst sehr langsam und stürzt dann irgendwann ab.
Wieviel freien Arbeitsspeicher Sie zur Verfügung haben, bestimmen Sie am besten, indem Sie alle Fenster bis auf den Browser schließen und dann in der Kommandozeile den Befehl free -m eingeben. In der Spalte "verfügbar" können Sie ablesen, wieviel MB maximal noch zur Verfügung stehen.
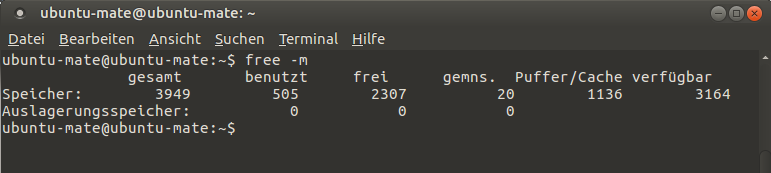
Ziehen Sie von diesem Wert zur Sicherheit mindestens 300 MB ab. Das Ergebnis ist der Höchstwert, den Sie OpenRefine zuordnen können.
Um jetzt das Limit zu erhöhen, bearbeiten wir die Einstellungsdatei von OpenRefine. Öffnen Sie die Datei refine.ini mit einem Texteditor (hier: Anwendungen / Zubehör / Pluma Text Editor) und ändern Sie den Wert in der Zeile REFINE_MEMORY=1400M auf 2000M und speichern Sie die Datei (STRG und S).
Wenn Sie über genügend freien Arbeitsspeicher verfügen, können Sie auch gleich ein höheres Limit setzen. Falls Sie nicht genügend freien Arbeitsspeicher haben, um das Limit zu erhöhen, dann bleibt Ihnen nichts anderes übrig als die Anzahl der zu verarbeitenden Daten zu reduzieren. Sie könnten im Folgenden beispielsweise nur einen Teil der heruntergeladenen XML-Dateien importieren.
Weitere Informationen: https://github.com/OpenRefine/OpenRefine/wiki/FAQ:-Allocate-More-Memory#linux-or-mac
Daten importieren
Im Menüpunkt "Create Project" auf den Button "Durchsuchen" klicken, in den Ordner Downloads wechseln und alle der im vorigen Kapitel gespeicherten XML-Dateien (
einstein-nebis...) auswählen. Mehrere Dateien können Sie, wie sonst auch üblich, mit der Taste Shift markieren (oberste XML-Datei anklicken, Shift gedrückt halten und unterste XML-Datei anklicken). Das Protokoll zum Download (Dateiendung.log) können wir nicht gebrauchen.Im nächsten Bildschirm könnten Sie von den ausgewählten Dateien noch wieder welche abwählen. Das ist aber nicht nötig. Klicken Sie gleich weiter oben rechts auf den Button "Configure Parsing Options".
Im letzten Bildschirm können Sie nun Einstellungen vornehmen, wie die XML-Dateien von OpenRefine interpretiert werden sollen. Gehen Sie wie folgt vor:
Klicken Sie als erstes im Vorschaubildschirm auf den Pfad
<record xmlns:xs="http://www.w3.org/2001/XMLSchema">. Es ist wichtig genau diese Stelle zu treffen. Wenn Sie mit der Maus darüber fahren, wird ein Kasten angezeigt, welche Daten OpenRefine als einen Datensatz interpretieren wird.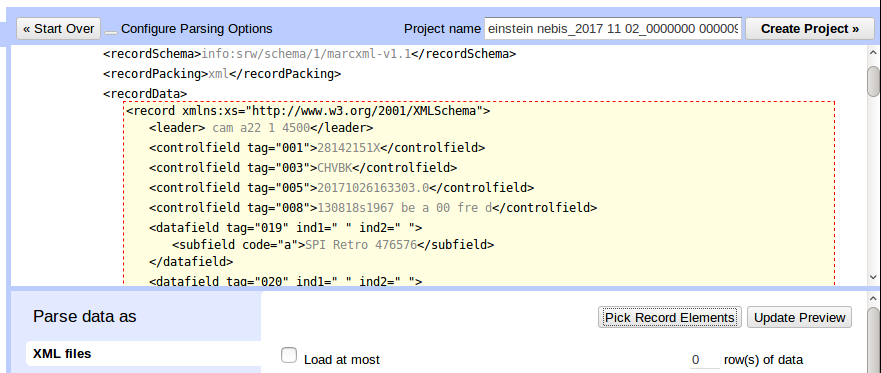
Nehmen Sie dann folgende weiteren Einstellungen vor:
- Checkbox "Store file source" deaktivieren
- Im Textfeld "Project Name" den hinteren Teil hinter dem Datum entfernen oder einen eigenen Namen vergeben
Abschließend können Sie das neue OpenRefine-Projekt mit diesen Daten erstellen, indem Sie oben rechts den Button "Create Project" drücken.
Daten prüfen
Klicken Sie bei der Spalte "All" auf das Dreieck und wählen Sie im Menü den Punkt Edit columns / Re-order / remove columns... aus.
So sollte die Spaltenstruktur aussehen:
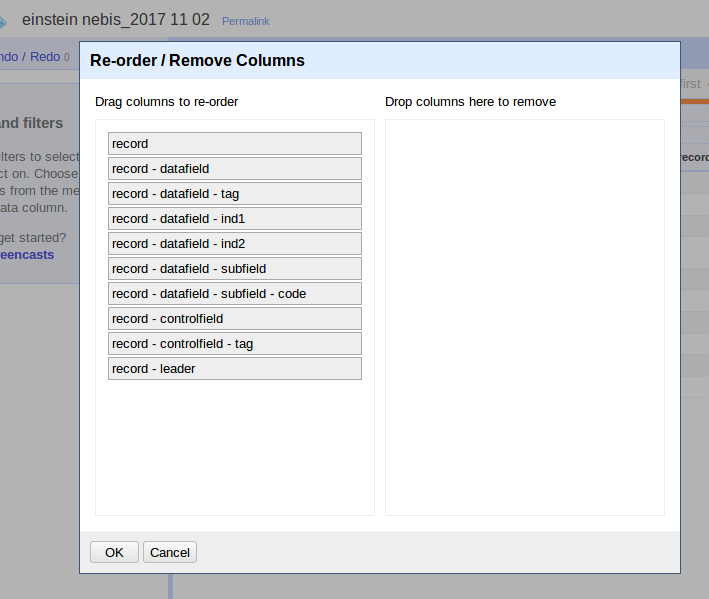
Achtung: Die weiteren Schritte beziehen sich auf diese Spaltennamen, daher müssen Ihre Spaltenbezeichnungen zwingend mit denen vom Screenshot übereinstimmen. Falls es bei Ihnen anders aussieht, ist beim Import etwas schiefgegangen.
Daten "massieren"
Bevor wir inhaltlich mit den MARC21-Daten arbeiten können, müssen wir diese zunächst umformen. OpenRefine "versteht" MARC21 nicht, sondern lädt die Daten wie andere XML-Dateien.
Um die MARC21-Daten so umzustrukturieren, dass sie in dem flachen Tabellenformat von OpenRefine benutzbar sind, sind zahlreiche Transformationsschritte notwendig. Damit Sie diese nicht manuell durchführen müssen, nutzen wir ein vorbereitetes Transformationsscript.
Rufen Sie die Datei openrefine-marc.json im Browser auf und kopieren Sie den gesamten Inhalt in die Zwischenablage (
STRGundAum alles zu markieren undSTRGundCum es in die Zwischenablage zu kopieren)Wechseln Sie in OpenRefine in den Tab "Undo / Redo" (neben "Facet / Filter" unterhalb des OpenRefine-Logos) und klicken Sie den Button "Apply...". Fügen Sie den Inhalt der Zwischenablage in das Textfeld ein (
STRGundV) und bestätigen Sie mit dem Button "Perform Operations".
Die Verarbeitung kann je nach Menge der Daten ein paar Minuten dauern. Anschließend ist die Struktur schon etwas handlicher. Etwa so sollte es aussehen:
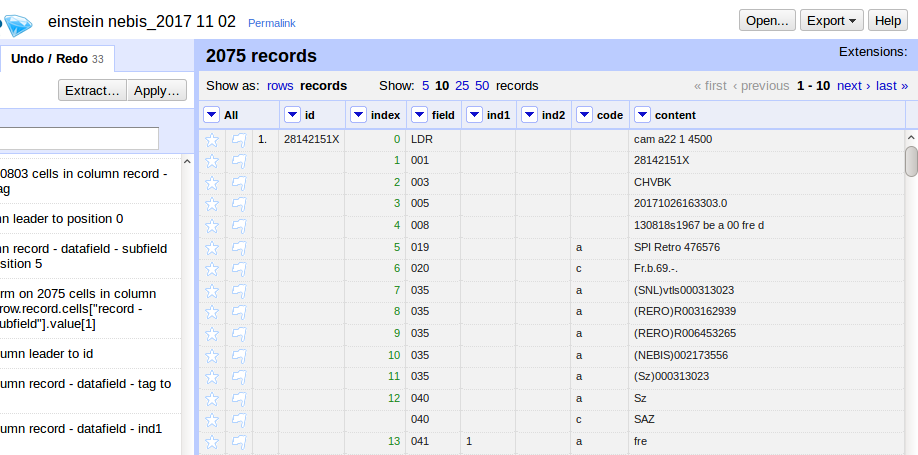
Aufgabe 2: MARC-Daten analysieren und neue Spalten für das Zielschema bilden
Jetzt wo die MARC-Daten alle einheitlich im Tabellenformat strukturiert vorliegen, können Sie für jedes Feld im Zielformat Dublin Core passende MARC-Felder und MARC-Codes auswählen/filtern und die ausgewählten Daten jeweils in neue "Dublin Core"-Spalten kopieren.
Nutzen Sie dabei die Empfehlung der Library of Congress (LoC) für einen "MARC to Dublin Core Crosswalk" als Orientierung.
Analyse
Um sich einen statistischen Überblick zu verschaffen, können Sie wie folgt vorgehen:
- Spalte
field/ Facet / Text facet - zeigt in einer Facette die Gesamtanzahl wie oft ein MARC-Feld in den Daten genannt wird (ggf. mehrmals pro Datensatz) - Spalte
field/ Edit cells / Blank down - jetzt wird in der Facette angezeigt wie viele Datensätze das jeweilige MARC-Feld mindestens einmal beinhalten - Klicken Sie in der Facette auf den Link "111 choices" (oder ähnlich), dann erhalten Sie eine tab-separierte Liste, die Sie in eine Tabellenverarbeitung kopieren können
- Vergessen Sie nicht, die Transformation "Blank down" über die Undo/Redo-Historie abschließend wieder rückgängig zu machen.
Neue Spalten für Zielschema bilden
Wenn Sie sich auf Basis der Empfehlung der LoC, der Statistik und Stichproben für ein Mapping von bestimmten MARC-Feldern und Codes auf ein Dublin-Core-Feld entschieden haben, ist das grundsätzliche Vorgehen dann wie folgt.
- Passende MARC Felder und Codes in den Spalten
fieldundcodemit Text-Facetten auswählen. - Ausgewählte Daten aus Spalte
contentmit der Funktionadd column based on column...in eine neue "Dublin Core"-Spalte kopieren (Name der Spalte ist das Dublin-Core-Feld). - Bei Bedarf die Daten in der neuen Spalte mit Transformationen bearbeiten, um z.B. Trennzeichen einzufügen.
- Zusammengehörige Werte (z.B. Person und ihre Lebensdaten) in der neuen Spalte mit der Funktion
join multi-valued cellszusammenführen. Damit nicht zuviel (z.B. mehrere Personen) zusammengeführt werden, muss dabei die Spalteindexvorne stehen. - Abschließend dann noch einmal mit der Funktion
join multi-valued cellsund dem bekannten Trennzeichen␟die Daten in einer Zeile pro Datensatz zusammenführen. Hierzu muss dann die Spalteidvorne stehen. Um die Performance zu verbessern, kann alternativ auch die Transformationrow.record.cells["Name der Spalte"].value.join("␟")(zusammen mit einer Facette "by blank" mit Wertfalseauf die Spalteid) auf die neuen Spalten angewendet werden.
Beispiel für "Autor/in" (MARC21 100a,D,d,e auf Dublin Core dc:creator):
- Passende MARC Felder und Codes auswählen.
- Die Zeilen-Ansicht wählen (show as: rows)
- Spalte
field/ Facet / Text facet / Wert100auswählen - Spalte
code/ Facet / Text facet / Werta,D,dundeauswählen (zur Auswahl mehrerer Werte mit der Maus darüber fahren und Link "include" anklicken)
- Ausgewählte Daten in eine neue Spalte kopieren
- Spalte
content/ Edit column / Add column based on column... / Name:creator/ Expression:value(unverändert)
- Spalte
- Bei Bedarf die Daten in der neuen Spalte mit Transformationen bearbeiten
- Trennzeichen zwischen Vor- und Nachname:
- Spalte
field/ Facet / Text facet / Wert100auswählen - Spalte
code/ Facet / Text facet / Wertaauswählen - Spalte
creator/ Edit cells / Transform... / Expression:value + ","
- Spalte
- Lebensdaten in runde Klammern:
- Spalte
field/ Facet / Text facet / Wert100auswählen - Spalte
code/ Facet / Text facet / Wertdauswählen - Spalte
creator/ Edit cells / Transform... / Expression:"(" + value + ")"
- Spalte
- Funktionsbezeichnung in eckige Klammern:
- Spalte
field/ Facet / Text facet / Wert100auswählen - Spalte
code/ Facet / Text facet / Werteauswählen - Spalte
creator/ Edit cells / Transform... / Expression:"[" + value + "]"
- Spalte
- Trennzeichen zwischen Vor- und Nachname:
- Zusammengehörige Werte in der neuen Spalte zusammenführen
- alle Facetten müssen geschlossen sein, bevor Sie fortfahren
- Spalte
id/ Edit column / Move column to end - Spalte
creator/ Edit cells / Join multi-valued cells... / Separator:
- Abschließend die Daten in einer Zeile pro Datensatz zusammenführen
- Spalte
id/ Edit column / Move column to beginning - Spalte
id/ Facet / Customized facets / Facet by blank... / Wertfalseauswählen - Spalte
creator/ Edit cells / Transform... / Expression:row.record.cells["creator"].value.join("␟")
- Spalte
- Ergebnis prüfen und ggf. nachbessern
- Spalte
creator/ Facet / Text facet - Spalte
creator/ Edit cells / Cluster and edit... / Method: nearest neighbor
- Spalte
Export
Wenn alle Spalten angelegt sind, dann können Sie die Daten für den Suchindex im Format TSV exportieren. Dazu sind noch zwei Schritte nötig:
- Spalte
id/ Facet / Customized facets / Facet by blank /false- um für den Export nur die oberste Zeile pro Record auszuwählen - Export / Custom tabular exporter... aufrufen, dort die Spalten
index,field,ind1,ind2,codeundcontentabwählen und im Reiter "Download" auf den ButtonDownloadklicken.
Wenn Sie die Datei herunterladen, wird diese im Ordner ~/Downloads gespeichert. Merken Sie sich den Dateinamen. In den Übungen in Kapitel 4 gehen wir von einem Dateinamen einstein.tsv aus. Wenn Ihre Datei anders heißt, müssen Sie diese entweder jetzt umbenennen oder in Kapitel 4.3 und 4.4 darauf achten, dass Sie den Dateinamen in den Befehlen entsprechend anpassen.
Lösung
Die Lösung für Aufgabe 2 (Mapping von MARC21 auf Dublin Core) ist auf der Seite Lösungen dokumentiert.